Roberto Busby

👋 Hi, I'm a Data Analyst with experience in data manipulation, business intelligence, and process automation. I love turning complex data into insights that drive positive change.
Visit my LinkedIn
Exploratory Data Analysis of Hospital Care for Diabetic Patients
Table of Contents
Introduction
My fascination with healthcare data’s complexities and its potential to yield insightful observations for patient care and hospital management inspired this project. The healthcare sector, with its intricate data structures and significant impacts, provides a unique analytical challenge. This project primarily aims to practice SQL skills by using advanced techniques like joins, CASE statements, GROUP BY and HAVING clauses, and subqueries and CTEs to extract and analyze data from a comprehensive healthcare dataset. While I aim to uncover patterns that demonstrate the power of data analysis in healthcare, it is important to note that this project is purely educational and not intended to influence actual healthcare decisions.
Key Findings
- Length of Hospital Stay Trends: Most diabetic patients were found to have short hospital stays, typically ranging from 1 to 4 days.
- Variation in Treatment by Medical Specialty Data analysis revealed that medical specialties such as thoracic surgery and cardiovascular surgery generally involve a higher number of procedures per patient.
- Correlation Between Lab Procedures and Hospital Stay: A distinct correlation was identified indicating that patients undergoing more laboratory procedures typically experience longer hospital stays.
Source
The dataset used in this project spans ten years (1999-2008) of clinical care from 130 U.S. hospitals and integrated delivery networks, focusing on hospital admissions for patients diagnosed with diabetes. It comprises over 100,000 instances and 50 features, covering an extensive array of data points including patient demographics, the medical specialty of the admitting physician, type of admission, length of hospital stay, laboratory tests performed, medications administered, and patient outcomes like readmission rates. This comprehensive dataset is available on Kaggle, a prominent platform hosting datasets and competitions for data science and machine learning. It is publicly accessible for analysis and educational uses, making it an excellent resource for exploring healthcare analytics.
Analysis
1. Data Preparation & Exploration
The initial step in preparing the dataset for analysis involved loading the data into a MySQL database, which was structured into two main tables: demographics and health. This organization facilitated a more efficient querying process by separating patient demographic information from their health-related data.
- Next, the data types in the tables were verified. Here is an example of this query for the
healthtable:SELECT column_name, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema = 'patient' AND table_name = 'health'; - Data Type Adjustments: Certain columns, like num_medications in the health table, were originally imported with varchar data types. These were converted to integer types to enable numerical operations essential for analysis.
- Handling Missing Values: The dataset contained several missing values, especially in the race and weight categories. For simplicity and to maintain data integrity, entries with missing race data were retained and categorized under a new label ‘?’, allowing for an inclusive analysis of demographic impacts without data loss.
2. Descriptive Queries
Below are the SQL queries used to examine time distributions, medical specialities, and potential disparities in treatment along with its respective output:
2.1 Distribution of Hospital Stays
Analyzed the distribution of the length of hospital stays by simulating a histogram, identifying a predominance of short-term stays (1-4 days), which highlights the operational dynamics and potential areas for improving patient care efficiency.
SELECT
ROUND(time_in_hospital, 1) AS length_of_stay,
COUNT(*) AS count,
RPAD('', COUNT(*) / 100, '*') AS bar
FROM
health
GROUP BY length_of_stay
ORDER BY length_of_stay;

This pattern is important for understanding hospital workflows and patient turnover.
3. Comparative Analysis
3.1 Medical Specialties and Procedures
This query identifies medical specialties that typically involve a higher number of procedures per patient, indicating areas with intensive procedural demands.
SELECT
medical_specialty,
ROUND(AVG(num_procedures), 1) AS avg_procedures,
COUNT(*) AS count
FROM
health
GROUP BY medical_specialty
HAVING count > 50 AND avg_procedures > 2.5
ORDER BY avg_procedures DESC;
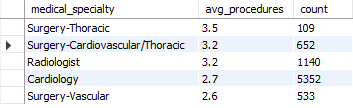
This analysis enhances understanding of procedural frequencies and aids in the hypothetical allocation of resources.
3.2 Potential Racial Disparities in Treatment
This query explores the differences in the number of laboratory procedures performed across different racial demographic groups.
SELECT
race,
ROUND(AVG(num_lab_procedures), 1) AS avg_num_lab_procedures
FROM
health AS h
JOIN
demographics AS d ON h.patient_nbr = d.patient_nbr
GROUP BY race
ORDER BY avg_num_lab_procedures DESC;
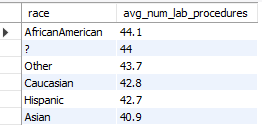
While the differences were nominal, ongoing monitoring and study of these trends are crucial to ensure healthcare equity and to address any emerging disparities.
4 Correlational Analysis
4.1 Lab Procedures and Hospital Stay Length
This query investigates the correlation between the number of lab procedures and the length of hospital stays.
SELECT
ROUND(AVG(time_in_hospital), 1) AS avg_time,
CASE
WHEN num_lab_procedures >= 0 AND num_lab_procedures < 25 THEN 'few'
WHEN num_lab_procedures >= 25 AND num_lab_procedures < 55 THEN 'average'
ELSE 'many'
END AS procedure_frequency
FROM
health
GROUP BY procedure_frequency
ORDER BY avg_time DESC;
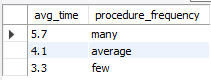
This relationship is analyzed to demonstrate how to detect and interpret healthcare data patterns, emphasizing the potential impact of procedural load on hospital stay durations.
5 Targeted Analysis
5.1 Efficiency of Emergency Admissions
This analysis examines the efficiency of emergency admissions by focusing on the duration of hospital stays compared to the average.
WITH avg_time AS (
SELECT AVG(time_in_hospital) AS avg_hospital_time
FROM health
)
-- Count patients staying less and more than the average duration and calculate percentages
SELECT
ROUND(100.0 * SUM(CASE
WHEN time_in_hospital < avg_hospital_time THEN 1
ELSE 0
END) / COUNT(*),
2) AS pct_below_average_stays,
ROUND(100.0 * SUM(CASE
WHEN time_in_hospital >= avg_hospital_time THEN 1
ELSE 0
END) / COUNT(*),
2) AS pct_above_or_equal_average_stays
FROM
health,
avg_time;

This helps to understand the distribution of hospital stays but also to quantify how often emergency admissions result in shorter-than-average stays, potentially indicating efficiency in patient management and resource utilization.
Conclusion
This project unveiled several insights into the healthcare management of diabetic patients:
- Short Hospital Stays: The majority of patients had brief hospital admissions, underscoring the efficiency of initial treatments but also raising questions about the adequacy of care for preventing readmissions.
- Specialty Resource Utilization: High procedural demands were notable in specialties such as thoracic and cardiovascular surgery, suggesting areas that might benefit from targeted resource allocation.
- Correlation of Lab Procedures with Hospital Stay: A direct correlation was observed between the number of lab procedures and the length of hospital stays, highlighting the complexity of cases managed and the resources utilized.
Reflecting on this project, I used my SQL knowledge to navigate the complexities of a healthcare dataset focused on diabetes care. The process involved data cleaning and preparation, including correcting data types and managing missing values, which were necessary for effective analysis. Utilizing SQL techniques like subqueries, CTEs, and complex joins deepened my understanding of real-world data applications. Engaging with healthcare data underscored the potential of data analytics in improving operational efficiencies. Overall, this experience has not only bolstered my analytical capabilities but also piqued my interest in the intersection of data science and healthcare.